


The Rise of The Large Language Models
The Generative AI and LLM story

The Rise of LLM’s
Today LLM’s have taken the world by storm be it text to text models, NVIDIA's latest text to video AI model or text to image models just like Stable Diffusion or MidJourney V5. All these models have one thing in common that all these are running on LLM’s ( Large Language Models ). In this newsletter we are going to see what are LLM’s, how is their architecture, LLM models and their potential Advantages and Threats they are having while they will be used in Future.
What are LLM’s ?
A large language model (LLM) is a language model consisting of a neural network with many parameters (typically billions of weights or more), trained on large quantities of unlabeled text using self-supervised learning or semi-supervised learning. A large language model, or LLM is a model that can recognize, summarize, translate, predict and generate text and other content based on knowledge gained from massive datasets. LLMs emerged around 2018 and perform well at a wide variety of tasks. This has shifted the focus of natural language processing research away from the previous paradigm of training specialized supervised models for specific tasks.

What are Large Language Models used for?
Language is more than used for human communication. Code is the language of computers. Large language models can be applied to such languages or scenarios in which communication of different types is needed. These models broaden AI’s reach across industries and enterprises, and are expected to enable a new wave of research, creativity and productivity, as they can help to generate complex solutions for the world’s toughest problems. Large language models are also helping to create reimagined search engines, tutoring chatbots, composition tools for songs, poems, stories and marketing materials, and more.

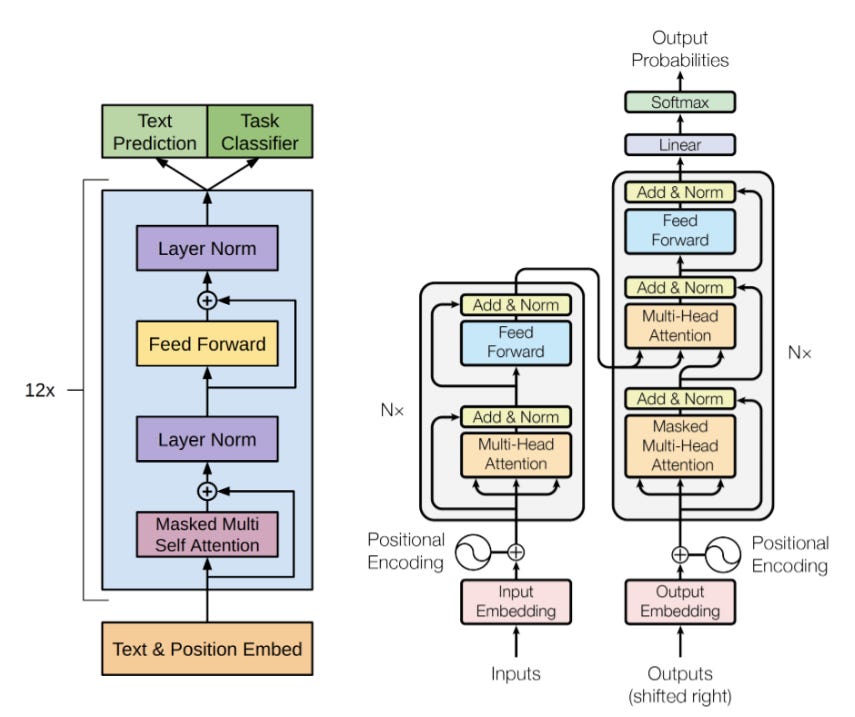
LLM Architecture
Large language models have most commonly used the transformer architecture, which since 2018, has become the standard deep learning technique for sequential data ( previously, recurrent architectures such as the LSTM ( Long short-term memory ) were most common ). In general, a LLM uses a separate tokenizer. A tokenizer maps between texts and lists of integers. The tokenizer is generally adapted to the entire training dataset first, then frozen, before the LLM is trained. A common choice is byte pair encoding.
Another function of tokenizers is text compression, which saves compute. Common words or phrases like "where is" can be encoded into one token, instead of 7 characters. The OpenAI GPT series uses a tokenizer where 1 token maps to around 4 characters, or around 0.75 words, in common English text. Uncommon English text is less predictable, thus less compressible, thus requiring more tokens to encode.
A tokenizer cannot output arbitrary integers. They generally outputs only integers in the range { 0 , 1 , 2 , ...V −1 } where V is called its vocabulary size. Some tokenizers are capable of handling arbitrary text (generally by operating directly on Unicode), but some do not. When encountering un-encodable text, a tokenizer would output a special token (often 0) that represents "unknown text". This is often written as [UNK], such as in the BERT paper.
Another special token commonly used is [PAD] (often 1), for "padding". This is used because LLMs are generally used on batches of text at one time, and these texts do not encode to the same length. Since LLMs generally require input to be an array that is not jagged, the shorter encoded texts must be padded until they match the length of the longest one.

List of Large Language Models
This is the list of some known large Language models which are being used today.



Advantages of LLM’s
Few benefits of Large Language Models are
The models are processed on large amounts of Data.
Another benefit is there versatility, from conversational chatbots to content generation these models can do things easier.
Limitations of LLM’s
Few limitations about Large Language Models are
Generative LLM’s have been observed to confidently assert claims of fact which do not seem to be justified by their training data, a phenomenon which has been termed "hallucination". It generally gives answers which are not relevant or do not exist also.
Generative LLM’s have been predicted to replace some of the jobs which humans are doing.
To train these huge models a lot of monetary funding and money is needed to spend on GPU’s to train the huge models, also these models consume huge energy which is also a growing concern.